

1、数据去重的应用场景:
不同角色的数据,剔除同一角色的重复数据,达到过滤数据的目的。
2、去重的几种方式
方式一:使用关键字distinct
注意:
a:count(distinct name)返回不重复记录的条数
b:必须放在select后,查询列的开始
c:只能在select语句中使用,不能在 insert, delete, update语句中使用
d:不能与all同时使用
e:distinct支持单列、多列的去重
f:执行效率要略高于group by去重
模拟数据:后面演示均参照这个模拟数据。


图1-模拟数据
SELECT DISTINCT university from user_profile //distinct单列查询单列查询结果:查询结果剔除了重复的北京大学、四川大学记录。
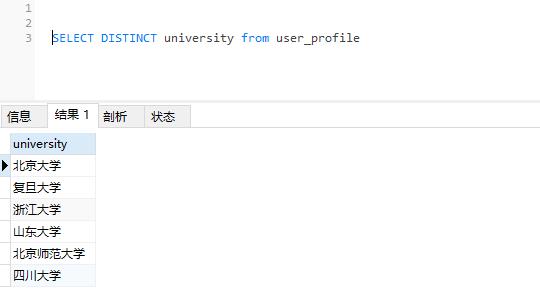
图2-distinct单列查询结果
SELECT DISTINCT university,gpa from user_profile //distinct多列查询多列查询结果:
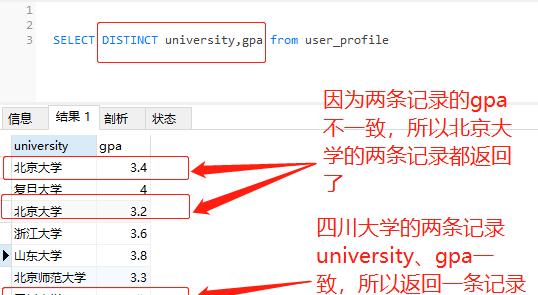
图3-distinct多列查询结果
方式二:利用group by分组来实现
注意:
a:group by 语句是根据一个或多个列对结果进行分组
b:group by 对查询结果进行了分组,自动将重复的项归结为一组
c:若需要select分组后的每一列,新版本数据库需要修改sql_mode,否则会报错
单列查询:
SELECT university from user_profile GROUP BY university //group by单列查询单列查询结果:
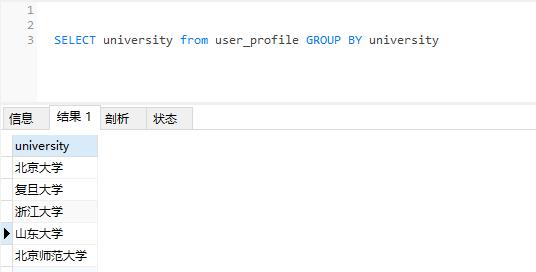
图4-group by单列查询结果
多列查询:
SELECT university,gpa from user_profile GROUP BY university,gpa //group by多列查询多列查询结果
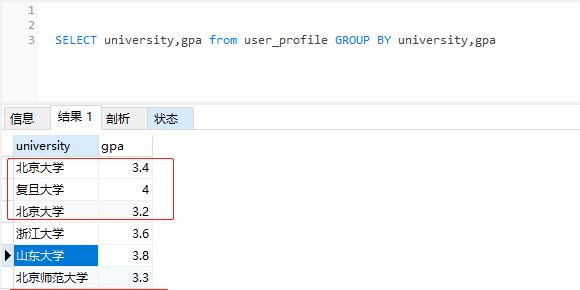
图5-group by多列查询结果
方式三:利用窗口函数row_number(),这儿则不演示了,前面文章提到过。
注意:
a:row_number()核心是利用 partition by对数据进行分组。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至2705686032@qq.com 举报,一经查实,本站将立刻删除。原文转载: 原文出处:

